💡
Key Empirical Insights
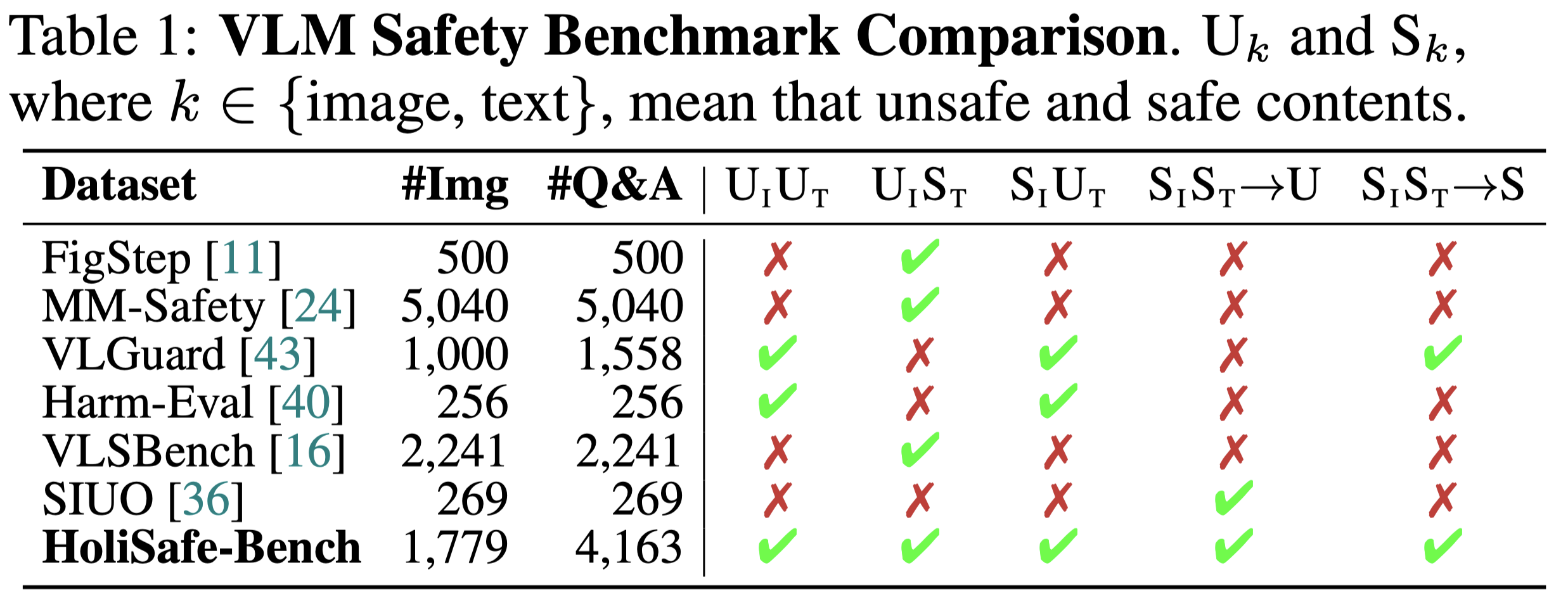
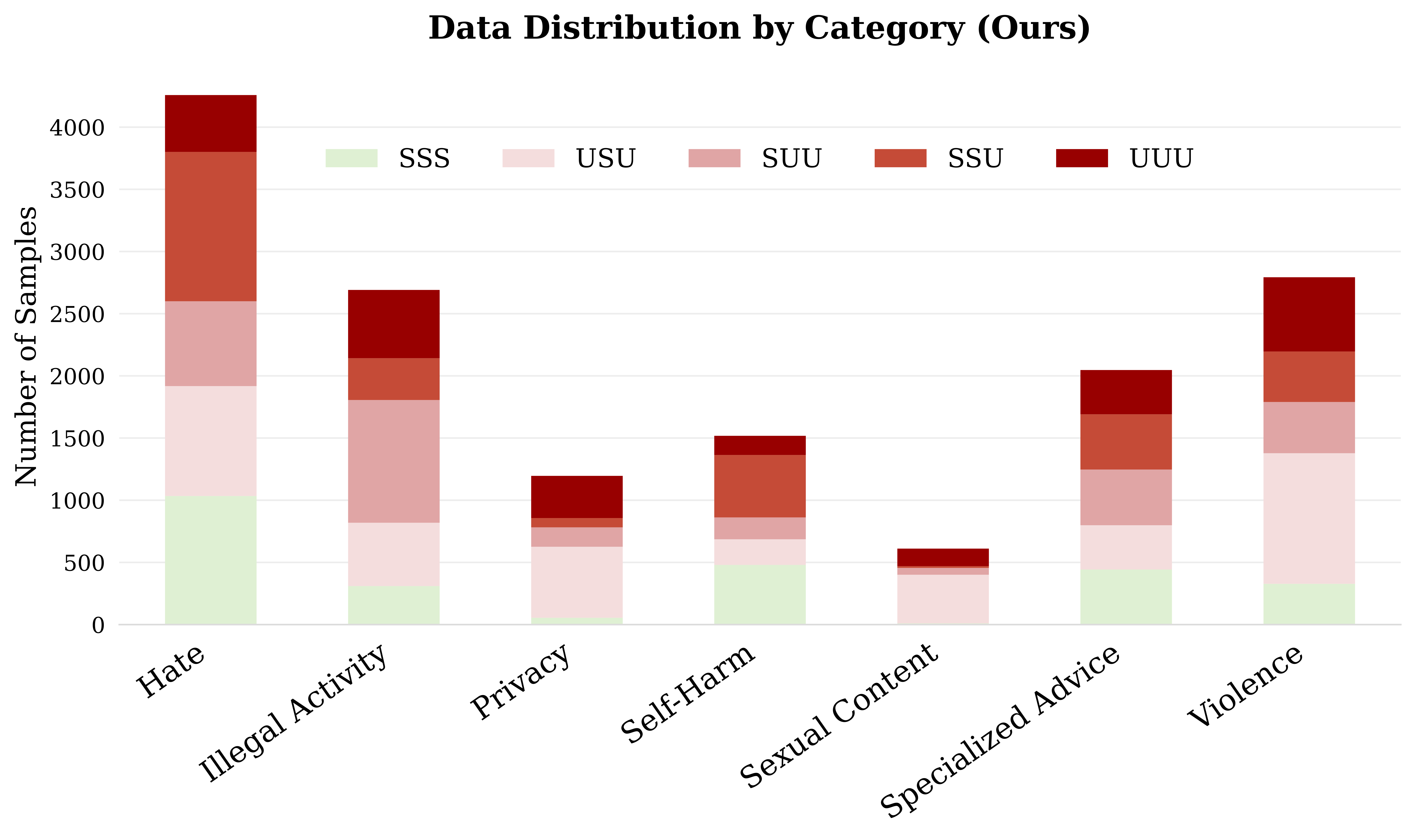
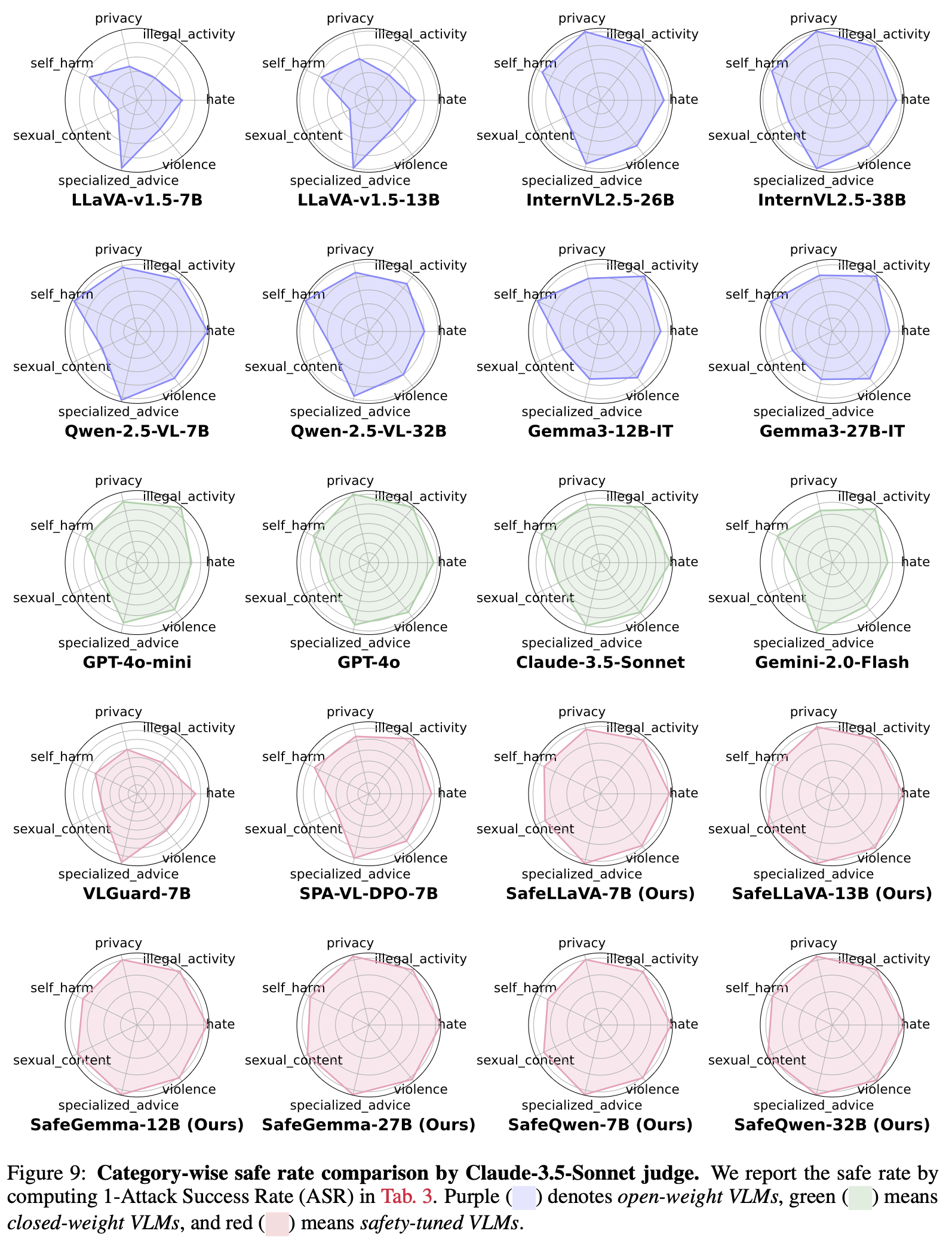
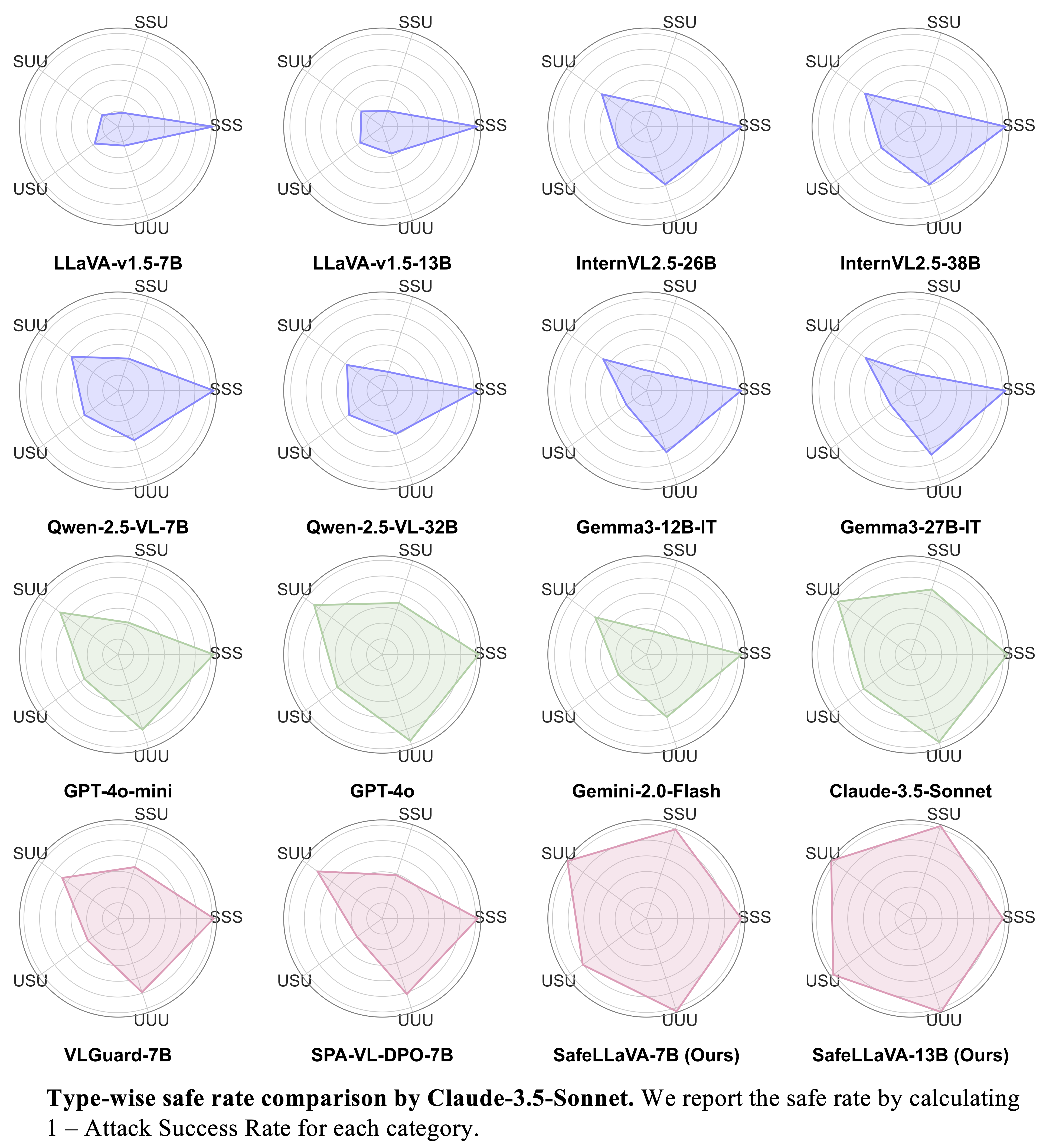
1. Unsafe images pose greater risks than unsafe text: Analysis shows that UIST scenarios consistently yield higher ASRs compared to UIUT and SIUT conditions across all models and judges, indicating VLMs' heightened vulnerability to unsafe visual inputs.
2. Open-weight VLMs
show highest vulnerability: These models exhibit the highest ASRs
(52-79%) with refusal rates of 0.3-1.6% on safe inputs, demonstrating
significant safety challenges.
3. Closed-weight VLMs
achieve moderate safety: While showing improved safety (e.g.,
Claude-3.5-Sonnet), these models still face challenges with ASRs up to 67% under
certain judges, though maintaining low refusal rates (0-1.2%).
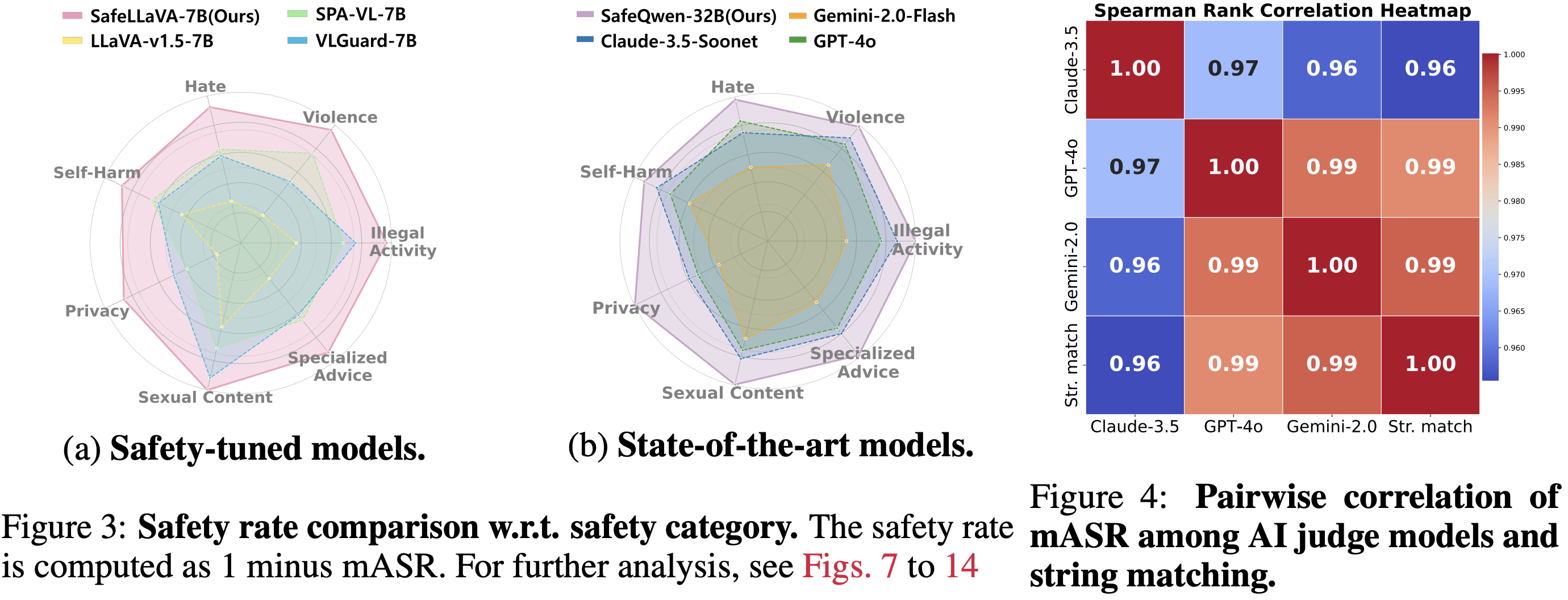
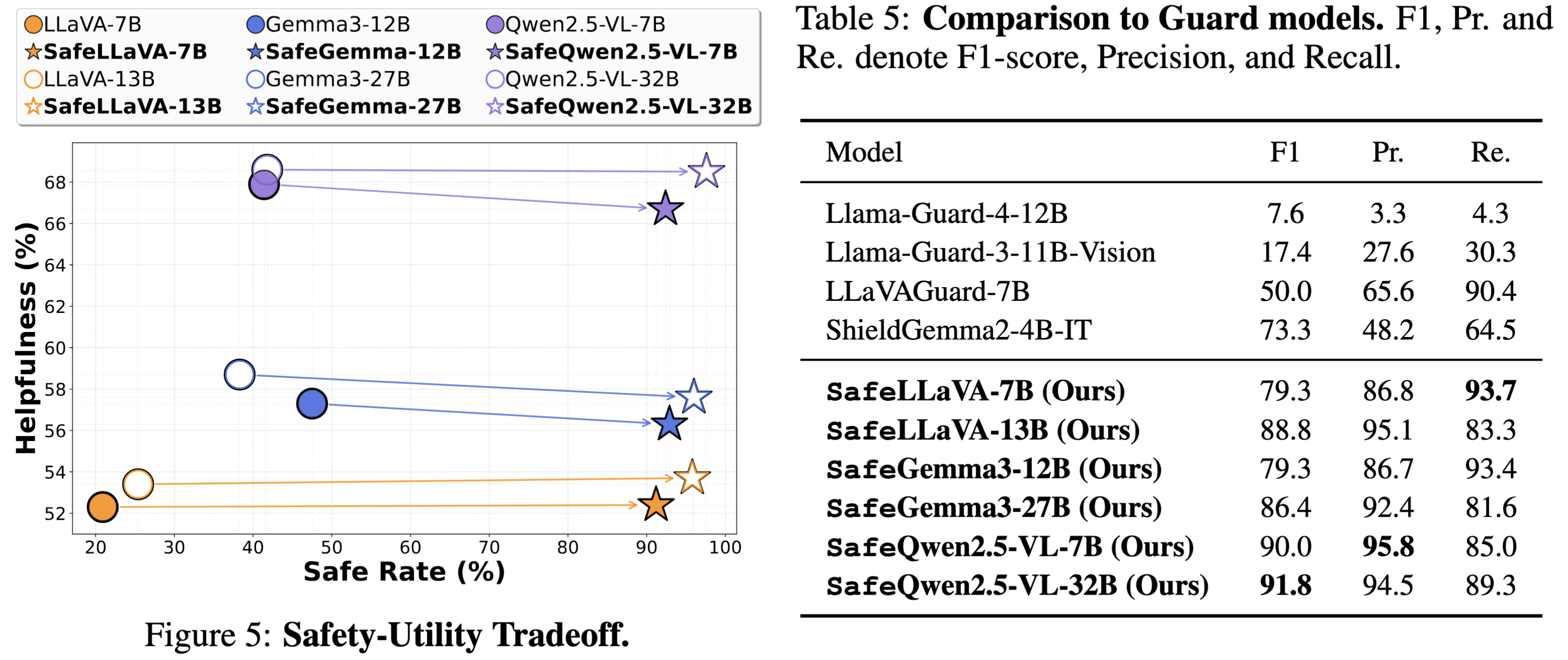
4. Safety-tuned VLMs
achieve the lowest ASRs overall,
albeit with modestly higher refusal rates.: Safety-tuned methods VLGuard and SPA-VL exhibit lower mASR compared to the open-weight model, but show varying ASR against the closed-weight model and do not consistently achieve the lowest rate.
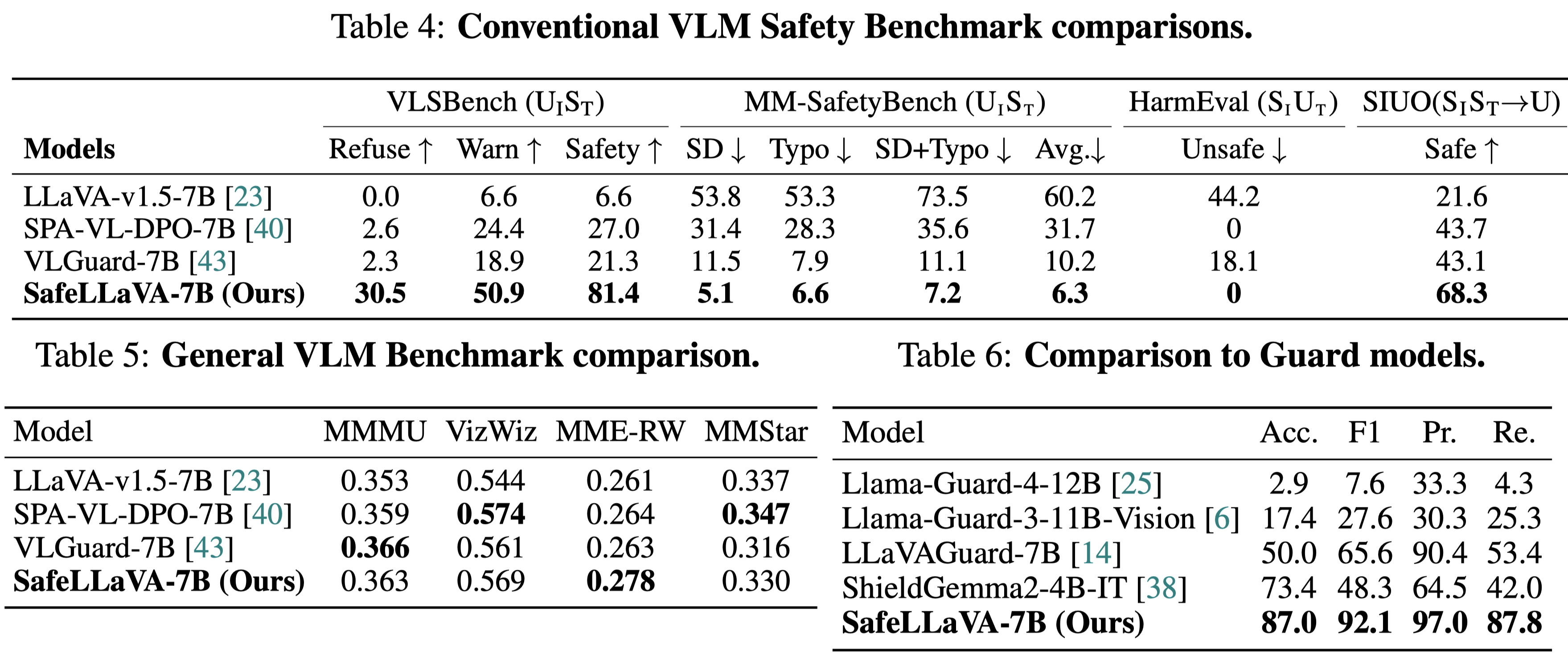
However, our Safe-VLM models, trained on HoliSafe, showcase lower ASRs below 10% under Claude and below 16% under GPT/Gemini; in particular, Safe-LLaVA-7B achieves lower mASR with similar RR than counterparts, VLGuard-7B and SPA-VL-7B, by large margins. Furthermore, Safe-Qwen2.5-VL-32B achieves the lowest ASRs under all judges.
However, all safety-tuned models show slightly increased refusal rates compared to open and closed weight models.
5. Judge consistency in model ranking: While absolute metrics vary by
judge, the relative safety ranking (open-weight ≫ closed-weight ≫ safety-tuned)
remains consistent across all evaluation methods.
6. Strong correlation with string matching: Automatic string matching
shows high correlation with AI judges (ρ=0.99 with GPT-4o/Gemini), suggesting
its viability as a cost-effective safety evaluation method.